开篇废话
之前有好几个项目因为偷懒用的 JSON 数据库又变成 0 字节灰飞烟灭了数了数炸了七八回了,想着还是找个阳间的东西存储数据 ,然后又看到妮可草经常安利 MeiliSearch (就感觉到快),于是就打算玩玩这玩意了
其实可以存 mongodb 之类的,这里作纯探索别的玩法
这样不用专门对搜索进行优化了,好麻烦,虽然最后结果是失败的(如果使用 %Like% 搜索,相当于每次搜索把数据库的表 grep 了一回,所以在这里我才想用 MeiliSearch
前排提醒,各版本已索引数据是不通用的,请及时备份。
更新篇传送门 https://blog.huggy.moe/posts/2022/4-meilisearch-2/
安装 & 配置
Arch Linux 倒是没什么好说的
pacman -S MeiliSearch
其它系统配置下源,或者直接下 bin 也行
参考 官方教程
然后编辑配置文件
nano /etc/MeiliSearch.conf
配置文件十分地简洁,改下绑定端口还有 masterkey 就好
# MeiliSearch configuration
#MEILI_ENV=
MEILI_HTTP_ADDR=192.168.233.2:7700
MEILI_MASTER_KEY=key@123
MEILI_NO_ANALYTICS=no
这里的 MEILI_HTTP_ADDR 就是监听端口,如果只在本地运行,那么根本不需要改,不填写默认是 127.0.0.1:7700
MEILI_MASTER_KEY 乱敲键盘就好(别碰特殊字符大概还好)
然后运行 && 开机启动
systemctl enable MeiliSearch --now
不出意外应该就成功运行了。
netstat -tunlp | grep MeiliSearch
# tcp 0 0 192.168.191.11:4000 0.0.0.0:* LISTEN 602200/MeiliSearch
使用
这里参照 官方教程
还有就是使用了 postman 请求 MeiliSearch 的工具 (官方的 curl 例子其实也很详细了,直接复制用改改也行)
用法其实和一些 noSql 数据库有点像,就是一种拿来存 json 数据的轮子啦,主要是 快 !
然而这个快 是建立在有分词的情况了,后面会说到这种分词的牺牲方面
鉴权
参考官方文档
一开始肯定要聊一下鉴权方面了,图省事的话,甚至可以不鉴权(别开放公网访问大概就行?)
有个 masterkey 懒一点话直接在 header 填上 masterkey 也行
也可以用 masterkey 生成 public key / private key 来使用
这里也顺便介绍下请求 melisearch 最基本的使用。
官方例子已经很明白了:
curl \
-H "X-Meili-API-Key: 123" \
-X GET 'http://localhost:7700/keys'
这里会返回 public key / private key :
{
"private": "8c222193c4dff5a19689d637416820bc623375f2ad4c31a2e3a76e8f4c70440d",
"public": "948413b6667024a0704c2023916c21eaf0a13485a586c43e4d2df520852a4fb8"
}
这里对 private / public 不是 RSA 那种非对称加密用到的,所以不用想到这方面,简单地来说 public key 大概是可以进行只读操作(也就是说我可以直接暴露 melisearch api 到前端)
而 private key 是可以对数据甚至表进行操作,约等于 master key
更多细节可以参考官方对鉴权的说明
然而这玩意在更改了 masterkey 后才会变 好随意(((
创建 index
官方文档
这里 MeiliSearch 的 index 相当于数据库的一个表名,然后这个表必须有个独特的字段(一般来说就是 id 啦)
curl \
-X POST 'http://localhost:7700/indexes' \
--data '{
"uid": "test",
"primaryKey": "id"
}'
这里的 uid 就是表名,然后 primaryKey 就是数据库索引的名字(比如说 id)。
然后 status code 提示 201 created 就表示创建成功了~
插入数据
官方文档
melisearch 插入数据就类似 nosql 数据库(比如 mongodb)
curl \
-X POST 'http://localhost:7700/indexes/test/documents' \
--data '[{
"id": 1,
"title": "test",
"author": "huggy"
}]'
注意 这里插入数据都是要包含在一个 array 内的,哪怕是只有一行数据也要用 [] 包住才行。
这就是最基本的插入数据请求了
其它家基本都是 insert 就这边是 adddocuments (sdk 里面是这样的名字)
查询数据
查询数据才是 melisearch 的厉害之处,就感觉到快。
curl \
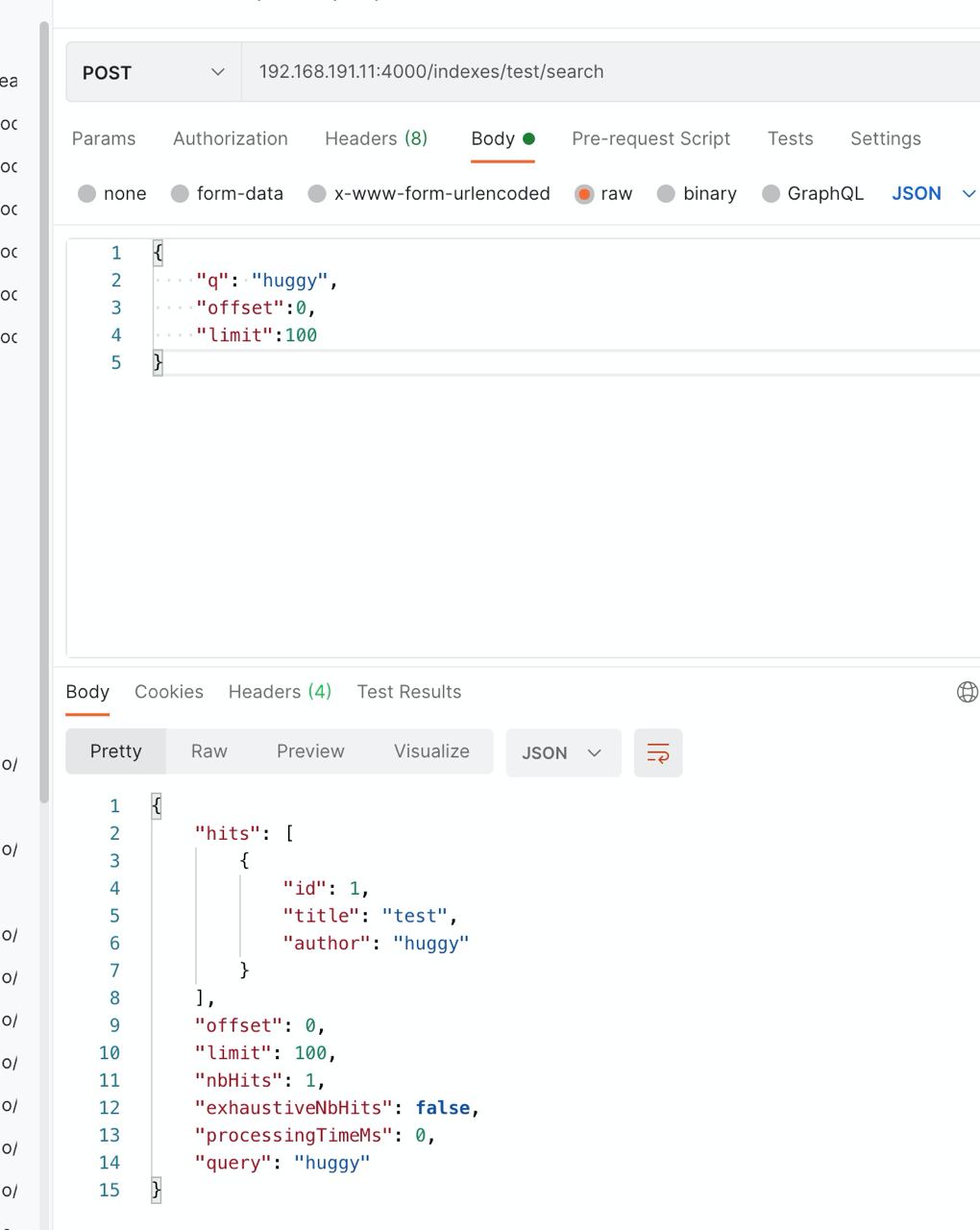
-X POST 'http://localhost:7700/indexes/test/search' \
--data '{ "q": "huggy", "offset":0,"limit":100 }'
这里的 q = query 就是要查询的文字
然后 filter 大概可以做更精确的
其它的还是看官方文档快点(
返回数据大概这样:
自由发挥
这里大概介绍完了基本用法,似乎还少了点,比如排序之类的?
很抱歉,meliseatch 对于排序之类的是弱化了的,不能在搜索的时候插入排序的规则。
截止 melisearch 0.20.0 好像还是这样
也就是可以全局排序,但是不能在搜索的时候附加排序规则进去(不像 mysql order by 就好了)
在 melisearch 有个 ranking rules 可以全局排序
| value | 垃圾说明 |
|---|---|
| typo | 按照错别字数量增加而排序 (没看懂 qaq) |
| words | 按照关键词匹配量而排序 |
| Proximity | 按照关键词之间距离而排序 |
| Attribute | 根据属性排名进行排序 |
| wordsPosition | 根据关键词在文中的位置排序 |
| exactness | 根据准确/相似性排序 |
| asc(id) | 根据字段升序排列 |
| desc(id) | 根据字段降序排列 |
简单的说明,建议直接看官方文档好点,塑料英语太烂了。
这里我做了,按照 id 来降序排序
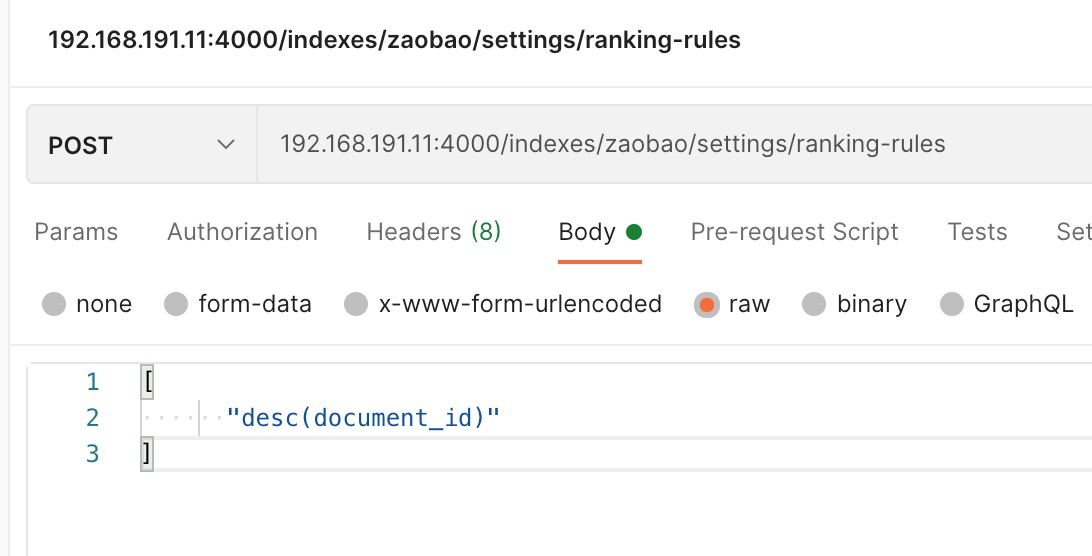
请注意,更改排序方式也不是实时生效的,在 0.24.0+ 以后有个 task api 可以看索引进度。
@zaobao_bot 截止 2021 年 6 月 28 日 就是使用 MeiliSearch 来存储数据的
坑点
说了这么多,好像 MeiliSearch 作为一个 nosql 好像非常好?
实际上不是的,他缺少了很多数据库该有的功能,正如名字一样,是用来搜索为主的。
弱化的排序功能,还有中文分词功能,直接导致了无法在正常中文(不能用空格分词的语言全部中招)项目里面使用(虽然官方已经用 jieba-rs 来分词了,但还是不合人意)
举个例子(新闻版权归早报所有)
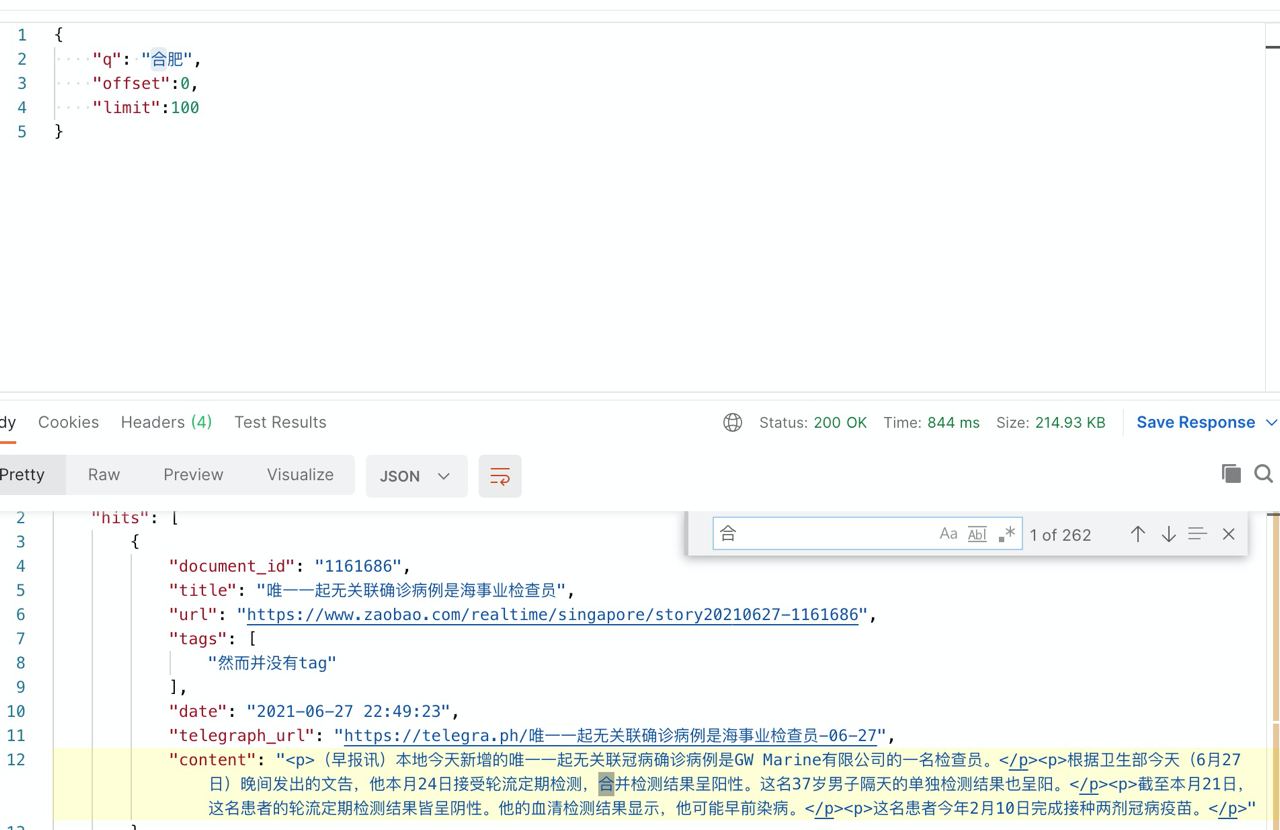
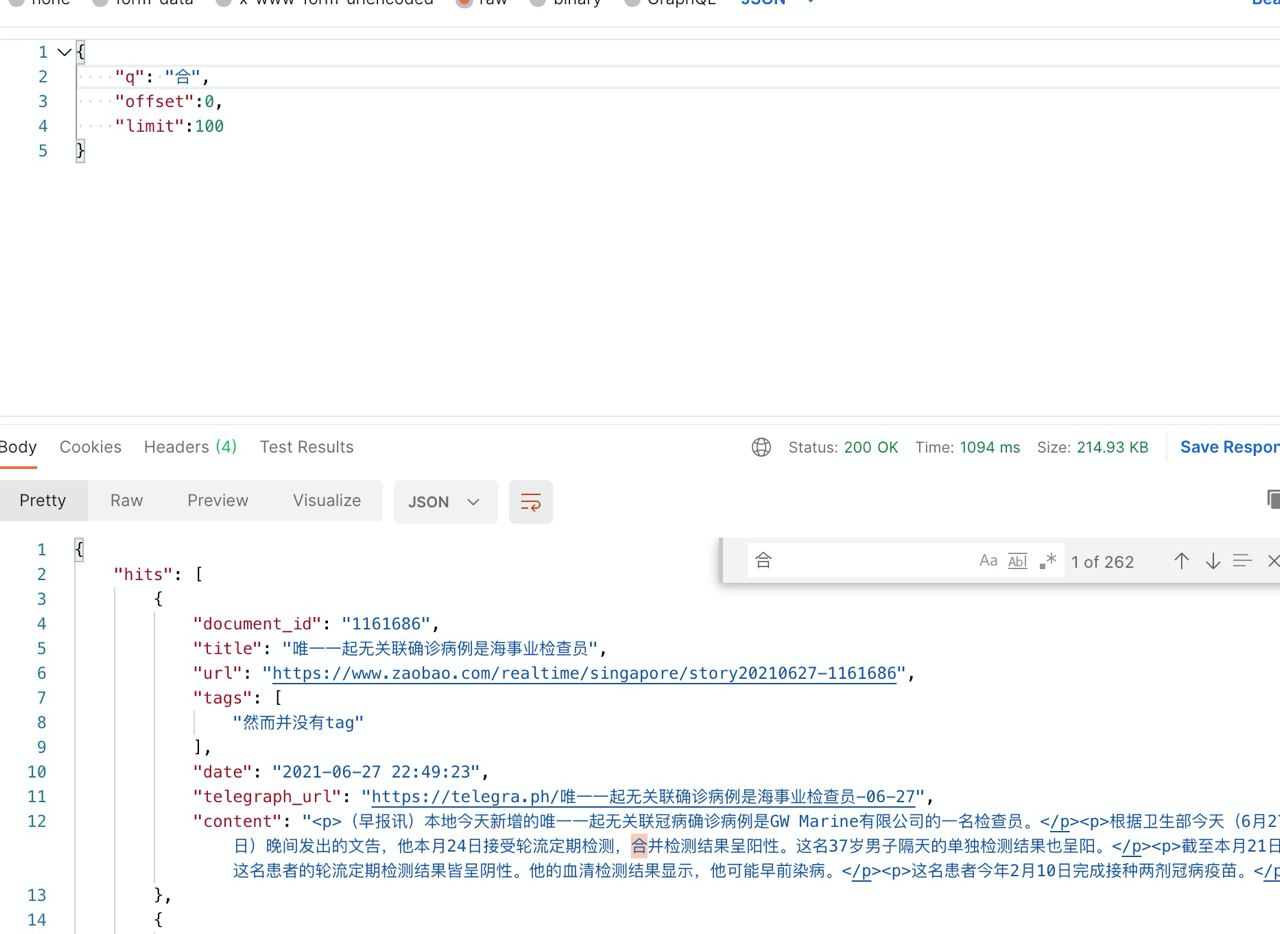
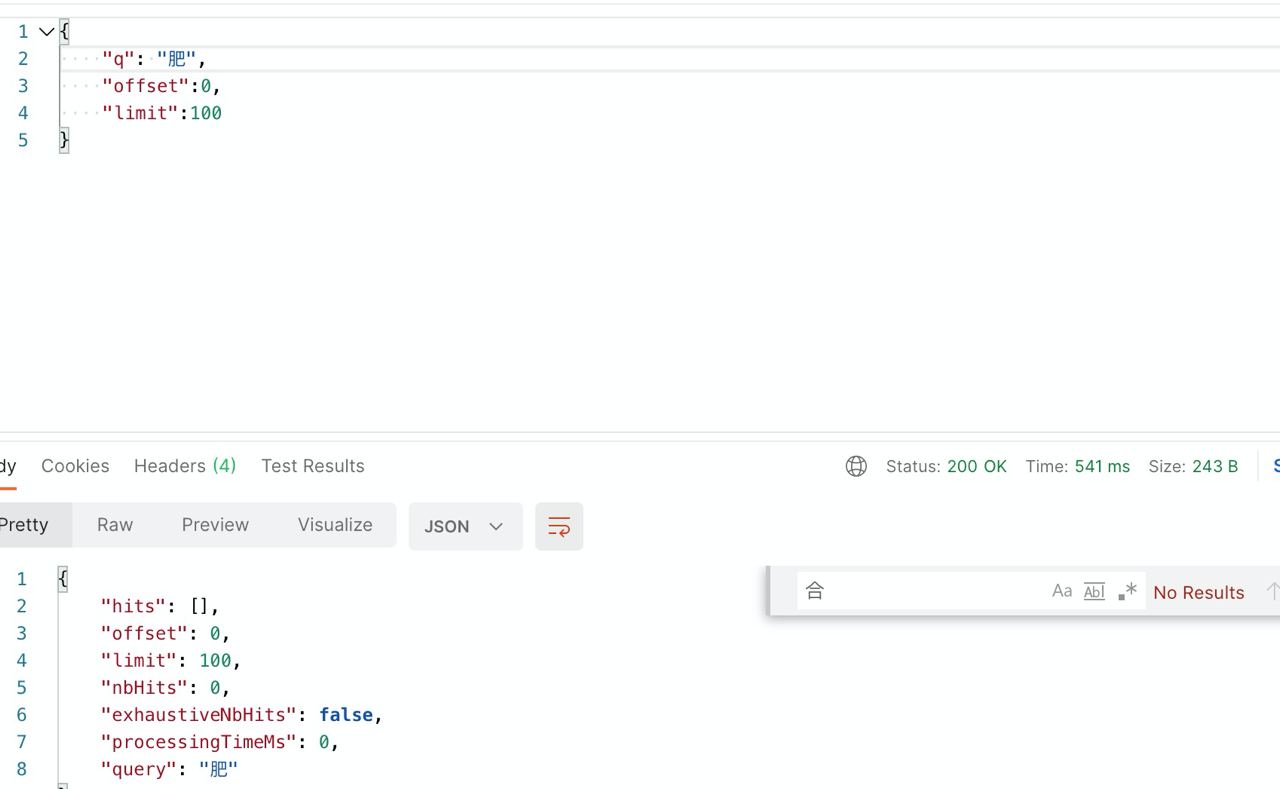
当我搜索 合肥 关键词的时候,MeiliSearch 不知道为什么只匹配到了 合,而 肥 是搜索无结果的。
这里我试了很多 ranking 参数,没啥解决办法。
参考官方文档
中文是依照 jieba 来生成的,如果 jieba 无法正确分词(比如合肥太短了 jieba 会认为是两个词 合 肥)那么搜索出来的结果就可能不是自己想要的了,这个问题至少在现在,因为 melisearch 的特性是无法解决的,直接用 mongodb 或者 redis 比较好点 大概。
完